
Some time ago professor Claudio Schifanella and I proposed a protocol acting like a decentralized mixer we called DMix (paper,demo,demo implementation). In this mixer, users interact to swap funds between each other. To maintain privacy, the output of the final transaction (the one from the mixer to the users) are all equal.
On the one hand, having many equal outputs in a transaction is the best (and easiest) way to increase privacy, since it maximize the number of possible IOmappings (i.e. the mapping between inputs and outputs of a transaction, see below for explicit definitions). On the other hand it has some practical drawbacks that prevent a smooth flow. It is important to note that the less friction the more the mixer is used, the higher the anonymity size, and therefore the higher the privacy. the principal drawbacks are:
Turns out that we share the same problem CoinJoins have. The problem is called Output Decomposition Problem and can be roughly stated as:
Output Decomposition Problem: for a given set of transaction input find the least number of outputs that maximize the possible IOmappings.
So this is what this post is about. We want to understand this Output Decomposition Problem by looking at the relevant literature and the proposed solutions. The end goal is to increase the privacy of DMix while making it more usable at the same time.
Insert table of contents
In the following we see some definitions related to the problem at hand.
It is easy to see that the less random the output are, the higher the number of possible IOmappings. Moreover, a higher number of IOmappings means higher privacy since many tracking heuristics will fail. See image below. Transactions T1 and T2 represent both a possible payment from Alice to Bob. Note that, assuming both transactions are in the blockchain, any adversary can see them as represented below
If I were an adversary, then:
It seems safe then to see the number of possible IOmappings as a proxy for privacy-measurement (but as mentioned IOmappings alone can not be a parameter since it can increase transaction fees and usability if done naively like original DMix):

We can now try to find the solution. To do that we will look at the following papers:
Surprisingly, I could not find other papers dealing with the problem at hand directly. Of course many decentralized mixer proposals do acknowledge the problem, but their solutions are either naive or not treated at all. 2
The authors introduce the idea of using the knapsack problem to increase the number of possible IOmappings, but no practical way to do that is presented
The core idea presented in this paper is to modify “original” transactions to maximize the number of possible mapping. The authors propose three strategies:

For easiness of explanation, we start from output dissection. The authors present an algorithm such that given two sets of inputs splits the biggest output in a way that leaves room for more IOmappings. Looking at the figure above it is easy to spot the general idea of the algorithm: the difference diff between the two sets is computed, and then the biggest output o is split into o1 = o − diff and o2 = o − o1. this naturally leads to multiple IOmapping possibilities.
Then, the authors argue that output dissection has no effect on the inputs, so a shuffle of them is proposed. Of course the two kinds of dissection can be joined together into a full fledged algorithm.
In the latter part of the paper, the authors argue that this splitting method decrease traceability of CoinJoin transactions.
Differently from [Mau], the paper by Wan et al. focuses only on the outputs of the transactions.More clearly, instead of splitting outputs based on some difference between the inputs, [Ni22] focuses on a real re-decomposition of the outputs.
The authors present a multi-round protocol that, starting from the original outputs, creates new derived outputs. The number of rounds is decided beforehand: the higher the number of rounds (up to a threshold) the higher the number possible IOmappings. of course, the transaction broadcasted to the blockchain is the one with the derived output.
the algorithm can be summarized in this way. given n original outputs oo1, ..., oon ordered from the highest amount to the lowest, at the first round the algorithm starts by computing the difference between the highest and the second-highest output. In general at round i the difference computed is
δi = oo1 − ooi + 1
. Then δi is subtracted from all oos, but the i + 1-th one.
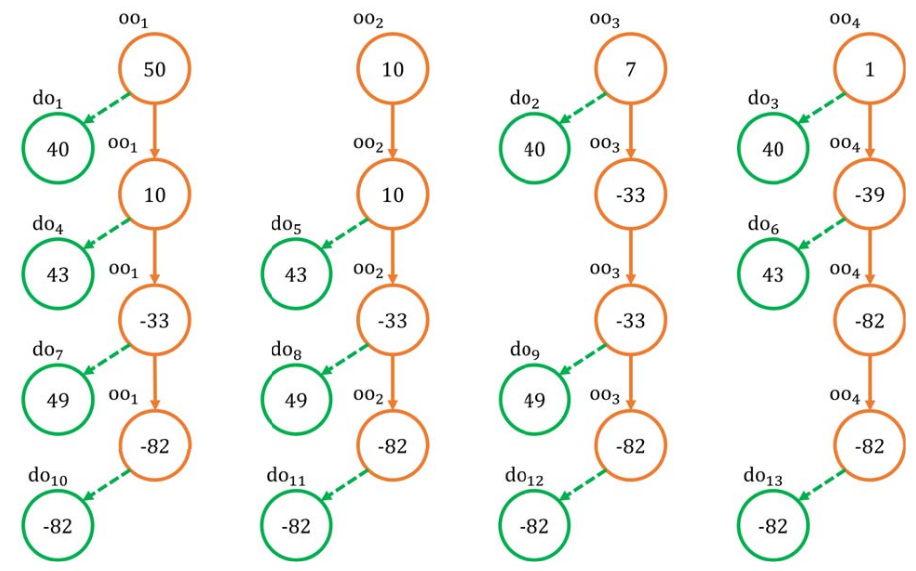
With reference to the figure above:
You may see that from 4 oos in the example, we have 13 derived outputs do at the end. I t is easy to see that this maximizes the number of possible mappings.
There is one problem: how to deal with negative amounts? Here the solution is to introduce compensatory outputs: a third party service (or a pool) participates to the transaction and the decomposition to help achieving privacy in exchange of a fee. Using the compensatory outputs co the situation is like the figure below:
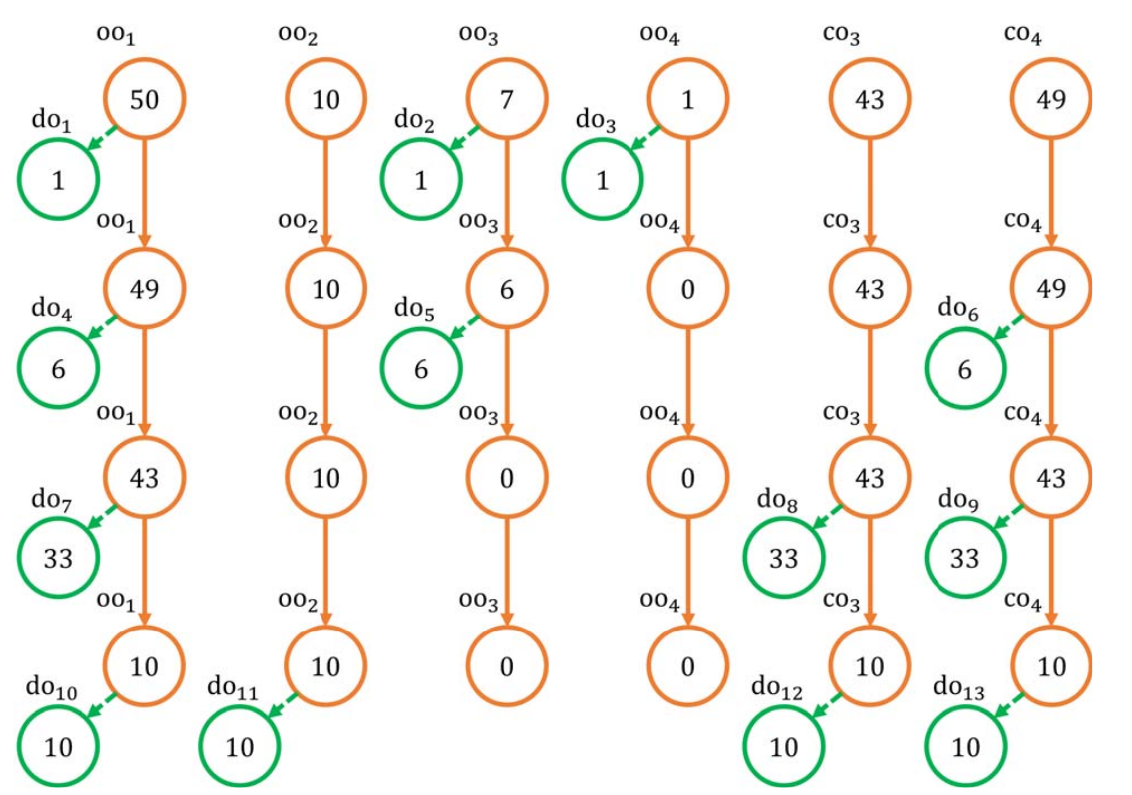
That’s because if the second output is the payment, then there is no reason to use more than one input, since any of the inputs alone would pay for it.↩︎
I may very well be wrong here! I you know about some other paper on the topi I would be very glad to edit the post and include it. you may write to me at @fadibarbara on Telegram or an email at me [at] fadibarbara.it .↩︎
I hope you liked this post. If you have comments, the best way to express them is by going on Telegram and comment on the dedicated post on the group.
Alternatively you can write me in private on Telegram or an email at me at fadibarbara .it .